A seahorse’s genetic instruction book is giving biologists a few insights into the creature’s odd physical features and rare parenting style.
Researchers decoded a male tiger tail seahorse’s (Hippocampus comes) genome and compared it to the genomes of other seahorses and ray-finned fishes. The analysis revealed a bevy of missing genes and other genetic elements responsible for enamel and fin formation. The absence of these genes may explain their tubelike snouts, small toothless mouths, armored bodies and flexible square tails, the team reports online December 14 in Nature.
Although H. comes may be short a few genes, the seahorse has a surplus of other genes important for male pregnancy — a trait unique to seahorses, sea dragons and pipefish. These genetic differences suggest the tiger tail seahorse has evolved more quickly than its relatives, the researchers conclude.
Famous footprints of nearly 3.7-million-year-old hominids, found in 1976 at Tanzania’s Laetoli site, now have sizable new neighbors.
While excavating small pits in 2015 to evaluate the impact of a proposed field museum at Laetoli, researchers uncovered comparably ancient hominid footprints about 150 meters from the original discoveries. The new finds reveal a vast range of body sizes for ancient members of the human evolutionary family, reports an international team led by archaeologists Fidelis Masao and Elgidius Ichumbaki, both of the University of Dar es Salaam in Tanzania. A description of the new Laetoli footprints appears online December 14 in eLife.
Scientists exposed 14 hominid footprints, made by two individuals as they walked across wet volcanic ash. More than 500 footprints of ancient horses, rhinos, birds and other animals dotted the area around the hominid tracks. Like previously unearthed tracks of three individuals who apparently strode across the same layer of soft ash at the same time, the latest footprints were probably made by members of Australopithecus afarensis, the team says. Best known for Lucy, a partial skeleton discovered in Ethiopia in 1974, A. afarensis inhabited East Africa from around 4 million to 3 million years ago.
All but one of the 14 hominid impressions come from the same individual. Based on footprint dimensions, the researchers estimate that this presumed adult male — nicknamed Chewie in honor of the outsized Star Wars character Chewbacca — stood about 5 feet 5 inches tall and weighed nearly 100 pounds. That makes him the tallest known A. afarensis. The team calculates that the remaining hominid footprint was probably made by a 4-foot-9-inch female who weighed roughly 87 pounds. Stature estimates based on the other three Laetoli footprint tracks fall below that of the ancient female.
Lucy lived later than the Laetoli crowd, around 3.2 million years ago, and was about 3 ½ feet tall. If Laetoli’s five impression-makers were traveling together, “we can suppose that the Laetoli social group was similar to that of modern gorillas, with one large male and a harem of smaller females and perhaps juveniles,” says paleontologist and study coauthor Marco Cherin of the University of Perugia in Italy.
Chewie’s stature challenges a popular assumption that hominid body sizes abruptly increased with the emergence of the Homo genus, probably shortly after A. afarensis died out, Cherin adds.
The new paper presents reasonable stature estimates based on the Laetoli footprints, but “we don’t have a firm idea of how foot size was related to overall body size in Australopithecus,” says evolutionary biologist Kevin Hatala of Chatham University in Pittsburgh. Masao’s group referred to size data from present-day humans to calculate heights and weights of A. afarensis footprint-makers. That approach “could lead to some error,” Hatala says.
Stature estimates based on footprints face other obstacles, says paleoanthropologist Yohannes Haile-Selassie of the Cleveland Museum of Natural History. For instance, some tall individuals have small feet and short folks occasionally have long feet. It’s also unclear whether the new footprints and those from 1976 represent a single group, or if some smaller footprints were also made by males, Haile-Selassie adds. Cherin’s proposal that large A. afarensis males controlled female harems “is a bit of a stretch,” Haile-Selassie says.
The new report doesn’t document surprisingly large size differences among members of Lucy’s kind, Haile-Selassie adds. A. afarensis fossils previously excavated in Ethiopia include a partial male skeleton now estimated by Haile-Selassie and his colleagues to have been only about three inches shorter than Chewie’s reported height (SN: 7/17/10, p. 5).
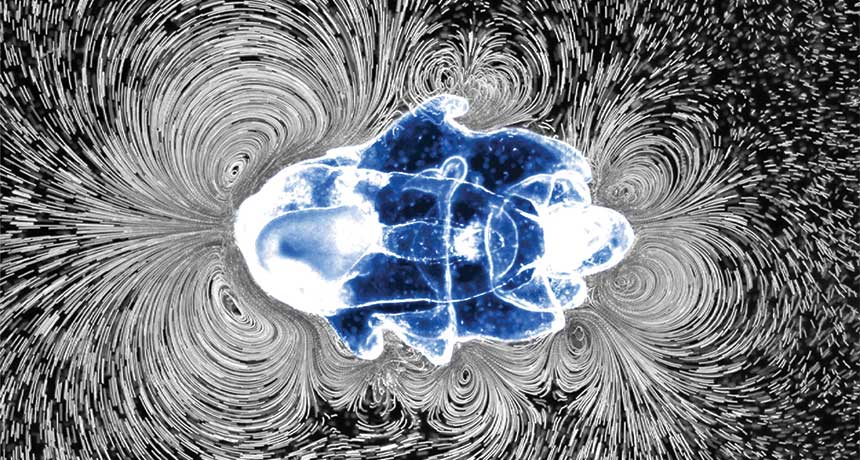
A baby starfish scoops up snacks by spinning miniature whirlpools. These vortices catch tasty algae and draw them close so the larva can slurp them up, scientists from Stanford University report December 19 in Nature Physics.
Before starfish take on their familiar shape, they freely swim ocean waters as millimeter-sized larvae. To swim around on the hunt for food, the larvae paddle the water with hairlike appendages called cilia. But, the scientists found, starfish larvae also adjust the orientation of these cilia to fine-tune their food-grabbing vortices.
Scientists studied larvae of the bat star (Patiria miniata), a starfish found on the U.S. Pacific coast, by observing their activities in seawater suffused with tiny beads that traced the flow of liquid. (Watch a video of the experiment.) Too many swirls can slow a larva down, the scientists found, so the baby starfish adapts to the task at hand, creating fewer vortices while swimming and whipping up more of them when stopping to feed.
People hunted and foraged year-round in the thin air of China’s Tibetan Plateau at least 7,400 to 8,400 years ago, a new study suggests. And permanent settlers of the high-altitude region might even have arrived as early as 12,000 to 13,000 years ago.
Three lines of dating evidence indicate that humans occupied the central Tibetan Plateau’s Chusang site, located more than 4,000 meters above sea level, at least 2,200 years earlier than previously thought, say geologist Michael Meyer of the University of Innsbruck in Austria and colleagues. Their report, published in the Jan. 6 Science, challenges the idea that the Tibetan Plateau lacked permanent settlers until farming groups arrived around 5,200 years ago.、 “Hunter-gatherers permanently occupied the Tibetan Plateau by around 8,000 years ago, which coincided with a strong monsoon throughout Asia that created wet conditions on the plateau,” Meyer says.
These early permanent residents hunted animals such as wild yaks and foraged for edible plants, including berries from sea buckthorn shrubs, in nearby river valleys at elevations more than 3,600 meters above sea level, Meyer suspects. Brief, summer forays to Chusang would have been difficult for people living below 3,300 meters above sea level, he adds. Even when mountain passes were clear of heavy snowfall and expanding valley glaciers, round trips from low altitudes to the central Tibetan Plateau would have taken 41 to 70 days, Meyer’s team estimates.
Researchers discovered Chusang in 1998. The site consists of 19 human hand- and footprints on the surface of a fossilized sheet of travertine, a form of limestone deposited there by water from a hot spring. The new age estimates for Chusang come from three measures: the decay rate of forms of radioactive thorium and uranium in travertine sampled in and around the prints; determinations of the time since quartz crystals extracted from the travertine were last exposed to sunlight; and radiocarbon measures of sediment and microscopic plant remains found on the travertine slab’s surface. Signs of long-term camping at Chusang have yet to turn up, but extensive excavations of the site have not been conducted, Meyer says. His group found chipped rocks and other stone tool‒making debris at two spots near Chusang’s hot springs. These finds are undated.
Previous research has suggested that hunter-gatherers occasionally reached the Tibetan Plateau’s northern edge by around 12,000 years ago (SN: 7/7/01, p. 7), and again from about 8,000 to 6,000 years ago, says archaeologist Loukas Barton of the University of Pittsburgh, who wasn’t involved in the study. But the new discoveries at Chusang may not necessarily point to permanent residence there. Those early arrivals likely spent a single summer or a few consecutive years at most on the plateau, Barton says. “That would not constitute a peopling of a region any more than our 1969 visit to the moon did,” he says.
Archaeological finds indicate that human populations expanded on the Tibetan Plateau between around 5,200 and 3,600 years ago, Barton says. Those groups cultivated barley and wheat at high altitudes and herded domesticated sheep and perhaps yaks, he says.
Before that time, Chusang might have supported a year-round occupation, says archaeologist David Rhode of the Desert Research Institute in Reno, Nev., who wasn’t involved in the study. But the site could easily have been occupied seasonally, he says. Unlike Meyer, Rhode estimates that Chusang was about a two-week walk from some lower-altitude campsites. “That’s not far at all for a human forager.”
New dates for Chusang also raise the possibility that rare gene variants that aid survival in high-altitude, oxygen-poor locales first evolved among hunter-gatherers on the Tibetan Plateau, Meyer says. But both Barton and Rhode doubt it.
The part of the brain that governs emotions such as fear and anxiety also helps mice hunt. That structure, the amygdala, orchestrates a mouse’s ability to both stalk a cricket and deliver a fatal bite, scientists report January 12 in Cell.
Scientists made select nerve cells in mice’s brains sensitive to light, and then used lasers to activate specific groups of those cells. By turning different cells on and off, the researchers found two separate sets of nerve cells relaying hunting-related messages from the amygdala’s central nucleus. One set controlled the mice’s ability to chase their prey. The other affected their ability to deliver a solid chomp and kill a cricket. “They’ve found these two behaviors — that are part of something we think of being very complex — are controlled by these two circuits,” says Cris Niell, a neuroscientist at the University of Oregon in Eugene who wasn’t part of the study. “You flip a switch to chase, you flip a switch to attack.”
Ramping both of those circuits up to high power at the same time even led mice to chase and capture a tiny bug-shaped robot that they would normally ignore or avoid.
“The central amygdala has been conceptualized as a center for emotion and fear and threat detection,” says study coauthor Ivan de Araujo, a neuroscientist at the John B. Pierce Laboratory in New Haven, Conn. Now, it seems that the structure also controls the relatively complex task of hunting.
Scientists don’t know how the new function relates to the amygdala’s better-known role as an emotional control center. But the amygdala does help control heart rate and blood pressure, which shift in emotionally charged situations but also need to be regulated when an animal is pursuing prey, de Araujo says.
The study also shows how even a complex task like hunting can be coordinated by different groups of very specialized nerve cells, or neurons, working together. In this case, one set of neurons made a signaling pathway that controlled chasing, while another controlled biting. Together, those neurons helped the mice grab dinner. “I think over the years we’ve become progressively more surprised by the behavioral specificity of these particular pathways,” says Anthony Leonardo, a neuroscientist at the Howard Hughes Medical Institute’s Janelia Research Campus in Ashburn, Va. “Certainly the evidence is mounting for a very strongly specific role for neurons.” Leonardo has found similarly specialized neurons in the dragonfly brain, with groups of neurons that run in parallel to each other controlling different types of movements.
Next, de Araujo says, his lab hopes to figure out what flips the neural switches in a mouse’s brain — how seeing or smelling potential prey triggers the amygdala to send the critter after a meal.
The sun has been in the same routine for at least 290 million years, new research suggests.
Ancient tree rings from the Permian period record a roughly 11-year cycle of wet and dry periods, climate fluctuations caused by the ebbing and flowing of solar activity, researchers propose January 9 in Geology. The discovery would push back the earliest evidence of today’s 11-year solar cycle by tens of millions of years.
“The sun has apparently been doing what it’s been doing today for a long time,” says Nat Gopalswamy, a solar scientist at NASA’s Goddard Space Flight Center in Greenbelt, Md., who was not involved in the study. Around every 11 years, the sun’s brightness and the frequency of sunspots and solar flares completes one round of waxing and waning. These solar changes alter the intensity of sunlight reaching Earth and, some scientists hypothesize, may affect the composition of the stratosphere and rates of cloud formation. Those effects could alter rainfall rates, which in turn influence tree growth.
Ancient trees may hold clues to similar cycles from long ago. In what is now southeast Germany, volcanic eruptions buried an ancient forest under debris roughly 290 million years ago. Paleontologists Ludwig Luthardt and Ronny Rößler of the Natural History Museum in Chemnitz, Germany, identified tree rings in the fossilized remains of the trees.
Measuring the widths of the rings, which show how much the plants grew each year, the researchers discovered a cycle in growth rates. The cycle lasted on average 10.62 years. This cycle reflects years-long rises and falls in annual rainfall rates caused by the solar cycle, the researchers propose. The cycle’s average length falls within the 10.44-year to 11.16-year length of the sunspot cycle seen over the last few hundred years.
Whether the solar and tree ring cycles are connected isn’t certain, says paleoclimatologist Adam Csank of the University of Nevada, Reno. Many studies suggest that it is not possible to clearly identify sunspot cycles in modern tree ring records, he notes. Other changes in Earth’s climate system or periodic insect outbreaks might contribute to tree ring widths, he says.
[T]he drug methadone appears to have fulfilled its promise as an answer to heroin addiction. Some 276 hard-core New York addicts … have lost their habits and none have returned to heroin — a 100 percent success rating. Methadone, a synthetic narcotic, acts by blocking the euphoric effect of opiates. Addicts thus get nothing from heroin and feel no desire to take it. — Science News. February 4, 1967.
UPDATE: The U.S. Food and Drug Administration approved methadone as a treatment for opiate addiction in 1972 but quickly recognized that it was no panacea. That same year, policy makers worried that methadone would produce addicts — as patients got high off the treatment itself (SN: 10/28/72, p. 277). Methadone can be deadly: In 2014, 3,400 people died of methadone overdoses. Although methadone is still used, drugs such as buprenorphine and naltrexone have joined the treatment arsenal for opiate addiction.
Electronic cigarettes may increase the risk of heart disease, researchers at UCLA report.
The team found that two risk factors for heart disease were elevated in 16 e-cigarette users compared with 18 nonsmokers.
“The pattern was spot-on” for what has been seen in heart attack patients and those with heart disease and diabetes, says cardiologist Holly Middlekauff, a coauthor of the study published online February 1 in JAMA Cardiology.
But because the study only looked at a small number of people, the results are not definitive — just two or three patients can skew results, John Ambrose, a cardiologist with the University of California, San Francisco cautions. Plus, he says, some of the e-cigarette users in the study used to smoke tobacco, which may have influenced the data. Even so, Ambrose called the study interesting, noting that “the medical community just doesn’t have enough information” to figure out if e-cigarettes are dangerous.
E-cigarette users in the study had heartbeat patterns that indicated high levels of adrenaline — also known as epinephrine — in the heart, a sign of heart disease risk. Researchers also found signs of increased oxidative stress, an imbalance of certain protective molecules that can cause the hardening and narrowing of arteries.
Previous research has connected oxidative stress to e-cigarettes. The new study targeted where it might occur and how it could contribute to heart disease, says Aruni Bhatnagar of the American Heart Association Tobacco Regulation and Addiction Center based at the University of Louisville in Kentucky.
This study “adds to the case that there may be some residual harm associated with e-cigarettes,” says Bhatnagar, whose editorial on e-cigarettes and heart risk appears in the same issue of JAMA Cardiology.
Previous studies have linked e-cigarettes to lung inflammation (SN: 7/12/14, p. 20) and examined the toxicity of e-cigarette vapor (SN: 8/20/16, p. 12). Nicotine, the addictive substance found in both tobacco and electronic cigarettes, is known to elevate adrenaline levels. To ensure that they were measuring the long-term effects of vaping and not just the presence of nicotine, the researchers had their subjects refrain from using e-cigarettes the day of the tests.
The findings are important, Middlekauff says, because they show that e-cigarette users’ hearts are in “flight or fight” mode all the time, not just when they are smoking.
The next step is to nail down exactly what in e-cigarettes is responsible for these effects on the heart, Middlekauff says. The researchers also want to compare e-cigarettes’ effects on the heart with tobacco cigarettes’.
“Electronic cigarettes aren’t harmless,” Middlekauff says. “They have real, measurable physiological effects and these physiological effects, at least the couple that we found, have been associated with heart disease.”
Genetic methods for counting new species may be a little too good at their jobs, a new study suggests.
Computer programs that rely on genetic data alone split populations of organisms into five to 13 times as many species as actually exist, researchers report online January 30 in Proceedings of the National Academy of Sciences. These overestimates may muddy researchers’ views of how species evolve and undermine conservation efforts by claiming protections for species that don’t really exist, say computational evolutionary biologist Jeet Sukumaran and evolutionary biologist L. Lacey Knowles. The lesson, says Knowles, “is that we shouldn’t use genetic data alone” to draw lines between species.
Scientists have historically used data about organisms’ ecological distribution, appearance and behavior to classify species. But the number of experts in taxonomy is dwindling, and researchers have turned increasingly to genetics to help them draw distinctions. Large genetic datasets and powerful computer programs can quickly sort out groups that have become or are in the process of becoming different species. That’s especially important in analyzing organisms for which scientists don’t have much ecological data, such as insects in remote locations or recently extinct organisms.
Knowles and Sukumaran, both of the University of Michigan in Ann Arbor, examined a commonly used computer analysis method, called multispecies coalescent, which picks out genetic differences among individuals that have arisen recently in evolutionary time. Such differences could indicate that a population of organisms is becoming a separate species. The researchers used a set of known species and tested the program’s ability to correctly predict the right number of species given certain variables. The program is good — maybe too good — at detecting the differences, Knowles says. If scientists don’t take other factors, such as geographical separation, into account, they may call genetically different groups separate species when they are merely subgroups of the same species.
Then again, it depends on what you mean by a “species,” says Rampal Etienne, an evolutionary community ecologist at the University of Groningen in the Netherlands. He developed the method that Knowles and Sukumaran analyzed. By one definition, a species is a genetically distinct lineage. “If that’s your species concept then, no, it’s not true that there are more species discovered by this method than there actually are,” Etienne says.
Biologists have long defined species primarily based on mating behavior and physical traits, not genetic similarity. Species are said to be reproductively isolated when they don’t mate either because they can’t or because they don’t for some reason (such as female fish choosing to mate with only red or blue males). Reproductive isolation doesn’t exclude two species from mating once in a while, says evolutionary biologist Ole Seehausen of the University of Bern in Switzerland. What’s important is that species that breed in the same area remain distinct. What’s more, “speciation is not a one-way road,” Seehausen says. When ecological conditions change, groups that had been going their separate ways may breed with each other again. For instance, female fish that choose mates based on color may breed with males of the non-preferred color when water becomes murky and obscures their vision. Computer programs can predict when speciation has started but can never forecast whether the groups will remain separate or will come back together, Seehausen says.
Using the biological criteria, the genetic method may seem to fall short, but genetic analyses simply aren’t designed to address such questions, Seehausen says. He agrees with Knowles and Sukumaran that genetic data should be used in combination with ecological and other studies to identify species.
Characterizing species based on their genes could still be a useful conservation tool, Etienne says, helping to preserve genetic diversity. A diverse set of genes can help a species adapt to changing environments, and a lack of diversity can doom it to extinction. Identifying diverse groups within a population could help researchers decide where to focus conservation efforts, Etienne says. “Whether they are two species or not is less important,” he says.
Estimates of global biodiversity are not affected by any shortcomings with the genetic analysis programs, Knowles says. Scientists use many types of data to determine the total number of species in a region or on Earth.
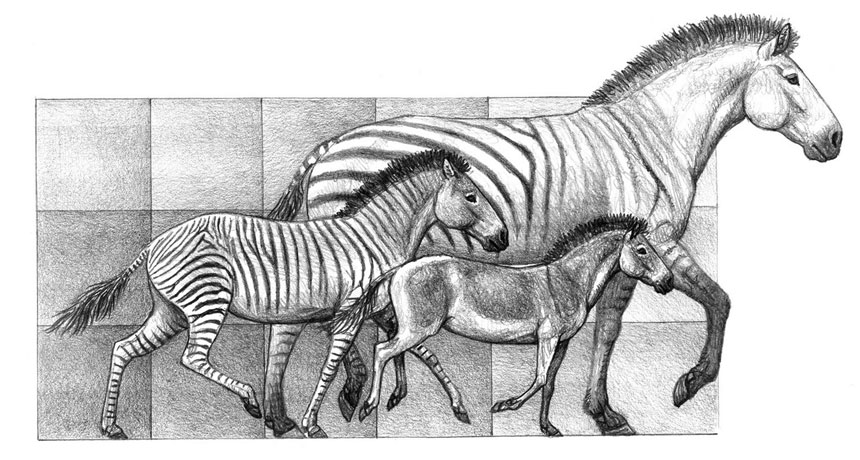
A cautionary tale in evolutionary theory is coming straight from the horse’s mouth. When ancient horses diversified into new species, those bursts of evolution weren’t accompanied by drastic changes to horse teeth, as scientists have long thought.
A new evolutionary tree of horses reveals three periods when several new species emerged, scientists report in the Feb. 10 Science. The researchers found that changes in teeth morphology and body size didn’t change very much during these periods of rapid speciation. “This knocks traditional notions that rapid diversification of new species comes with morphological diversification as well,” says paleontologist Bruce MacFadden of the University of Florida in Gainesville. “This is a very sophisticated and important paper.”
The emergence of several new species in a relatively short time is often accompanied by the evolution of special new traits. Classic notions of evolution say that these traits — such as longer teeth with extensive enamel — are adaptive, enabling an animal to succeed in a particular environment. In horses, the evolution of such teeth might permit a shift from browsing on leafy, shrubby trees to grazing on grasses in open spaces with windblown dust and grit.
“You can’t live on a grassland as a grazer and have short teeth,” says MacFadden, an expert in horse evolution. “You’ll wear your teeth down and that’s not a recipe for success as a species.”
Similarly, a big change in body size can indicate a move to a new environment. Animals that live in forests tend to be smaller and more solitary than the larger herd animals that live in open grasslands.
Paleontologist Juan Cantalapiedra and colleagues compiled decades of previous work to create an evolutionary tree of 138 horse species (seven of which exist today), spanning roughly 18 million years. The tree reveals three major branchings of new species: a North American burst between 15 million and 18 million years ago, and two bursts coinciding with dispersals into Eurasia about 11 million and 4.5 million years ago. The researchers expected to see evidence of an “adaptive radiation,” major changes in teeth and body size that allowed the new horse species to succeed. But rates of body size evolution didn’t differ much in sections of the family tree with low and high speciation rates. And rates of change in tooth characteristics were actually lower in sections of the tree with fast speciation rates, the team reports.
“It’s very tempting to see some change in body size, for example, and say, ‘Oh, that’s adaptive radiation,’” says Cantalapiedra, of the Leibniz Institute for Evolution and Biodiversity Science at the Museum für Naturkunde in Berlin. “But that’s not what we see.”
Cantalapiedra and his collaborators speculate that during the periods of rapid speciation, the environment was so expansive and productive that there just wasn’t a lot of competition to drive the evolution of adaptive traits. Perhaps, for example, North American grasslands were so rich and dense that there was enough energy for various species to evolve without having to develop traits that gave them an edge.
That scenario might be special to horses, says MacFadden, but it might not. Similarly, classic adaptive radiation scenarios might be true in many cases, but as this work shows, not always.